下午場實作¶
第一組 - PTT 鄉民在討論什麼 by 葉佩雯¶
第二組 - Kaggle 機器學習競賽 by 朱柏憲&吳東曄¶
Sample Code
Data-Set:需註冊Kaggle帳號下載
第三組 - 尋找新聞的蛛絲馬跡 by Mosky&潘玫樺¶
Sample Code & Data-Set
Data Source
第四組 - 探索熱賣電影的奧秘 by 彭欣雅¶
Sample Code
Data-Set:需註冊Kaggle帳號下載
環境安裝-Python 3.5¶
- 基本環境安裝
- sklearn 版本說明
- Windows 檔案IO說明
- jupyter 執行說明
這次workshop下午的實作部分,
講師提供了不同的data-set與sample code,
其中會用到以下的Packages:
- numpy
- scipy
- scikit-learn
- pandas
- matplotlib
- pydotplus
- wordcloud
- Pillow
- jieba
- beautifulsoup4
基本安裝:Anaconda¶
Anaconda 包含了以上大部分的 packages,不但安裝簡單,且提供jupyter的環境,
編寫code與執行結果都會顯示在同一畫面,對於分析資料來說是非常方便的!
(https://tw.pyladies.com/~marsw/jupyter_install.slides.html)
其餘Packages安裝¶
- 開啟終端機
- Mac:使用「Spotlight 搜尋」,搜尋「Terminal」,開啟
- Windows:開啟「開始功能表」,搜尋「cmd」,以「系統管理員身份執行」開啟
- jieba
pip install jieba
- wordcloud
- Mac/Unix:
pip install wordcloud - Windows:
- 下載符合對應系統版本(win32/amd64)的 wordcloud‑1.2.1‑cp35‑cp35m
- 使用
cd指令至下載位置 - 執行
python -m pip install xxxx.whl
- Mac/Unix:
- pydotplus
pip install pydotplus- Windows:
- 安裝Graphviz:下載msi
- 控制台>系統及安全性>系統>進階>環境變數>系統變數>Path
- 加上你的Graphviz安裝路徑,ex:
;C:\Program Files (x86)\Graphviz2.38\bin\; - 重新開機

sklearn 版本說明¶
scikit-learn版本需為0.18以上
import sklearn
sklearn.__version__
使用最新版本¶
在終端機執行conda upgrade scikit-learn
使用既有版本¶
由於0.18後更新了許多modules,名稱也有更動,
可參考官方文件改正:
from sklearn.cross_validation import train_test_split
from sklearn.cross_validation import ShuffleSplit
from sklearn.grid_search import GridSearchCV
但要注意「cross_validation」在0.20的版本後會刪除!
Windows 檔案IO說明¶
若遇到程式有使用到open來開檔,請務必加上「,encoding='utf8'」,
避免遇到cp950的UnicodeDecodeError。
open('data.txt',encoding='utf8')
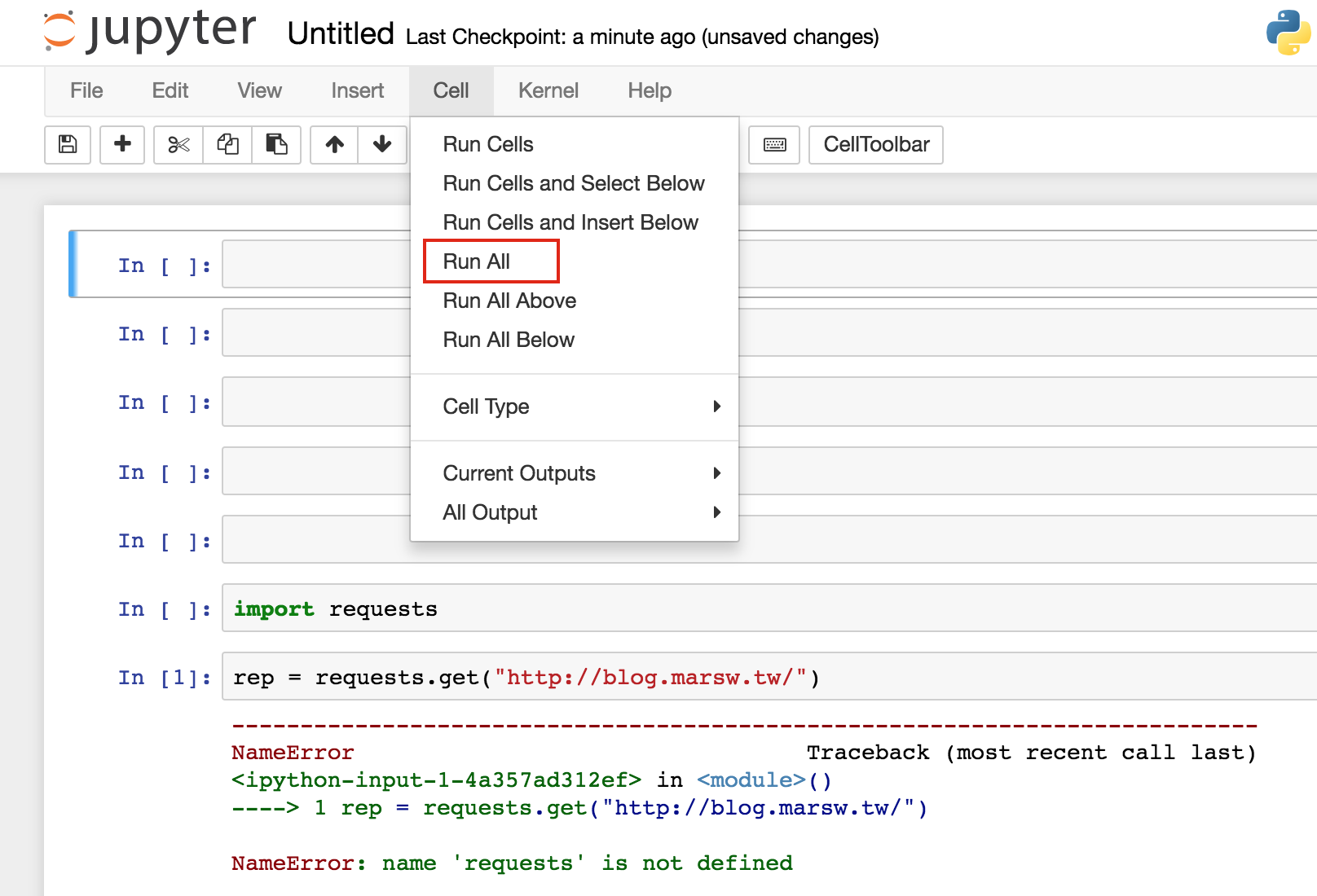
jupyter 執行說明-第一次執行¶
Cell > Run All
需要先將每一個程式區塊(Cell)跑過一次,
不然直接執行較下方的Cell,可能用到在上方宣告的變數,
而此時上方的Cell還沒執行過,也就是還沒宣告,就會出錯!
jupyter 執行說明-執行太久¶
左方 In[] 裡的 * 代表程式還在執行(執行成功會顯示數字),
如果有時候覺得執行太久(通常不會超過1min),
可用「停止」、「重啟」之後,再重新執行